MySQL GTID, Semi-Sync Replication and Partial View Caching: A good compromise to scale easy and cheap
For various reasons, I have often been involved in resolving infrastructural issues and performance gaps in MySQL deployments. I never envisioned my career focusing on database systems, yet it seems there is still a high demand for OLTP technologies in the Italian market, so here I am.
When you deal with a large dataset (over 500GB) with huge tables (more than 100 million rows), it's not hard to face performance issues. While many solutions exist for running analytical queries (OLAP) on large datasets by leveraging distributed systems, they are not typically "real-time" systems and often operate on stale data. When you have numerous, complex analytical queries — or expensive operations like COUNT(DISTINCT) — that must be submitted against a fresh, real-time system, you have no choice: you need to run them on your OLTP engine.
However, the impact of "read" and "write" queries on the same database host can be severe. Concurrency can lead to locking, which in turn causes significant slowdowns and, in the worst cases, fatal crashes. The common way to address this is by relying on Read/Write Splitting, where read queries (SELECT-like, or DQL) are sent to dedicated "read replicas" in a clustered scenario. But in heavily trafficked scenarios, even this is not enough.
The first, most straightforward solution is to review and optimize queries. This often means getting rid of the ORM at the code level and rewriting queries to leverage indexing and faster data lookup strategies. This is a very good exercise that in general pays the effort. However, there are still some queries that you cannot optimize.
Also due to the fact that you cannot change the structure of a production database, sometimes these optimizations are not doable by optimizing queries or improving tables indexing.
Often times you'll see so called "Temporary Tables" as a bendaid to speedup a single query. However, according to my own experience, a valuable tip is to avoid leveraging on temporary tables, which are connection-level tables that exist only for the duration of a MySQL connection, as they can be a performance bottleneck.
This brings us to a significant missing feature in MySQL: materialized views. Most other database management systems offer mechanisms to precompute the results of sophisticated queries as the underlying data changes. When the query is executed, the system can leverage this precomputed view. MySQL, however, does not implement this mechanism, likely due to its philosophy of simplicity.
Worth saying that there are also newSQL and shared storage solutions like AWS Aurora out there to address the scalability issues of a classical DMBS. Also, there are solutions like Vitess to implement transparent sharding. Or you could do partitioned tables to relief their weight. But all of these solutions may be really hard to implement and risky in a production stage, other than really expensive to implement and to maintain.
This is where the below robust yet simple architecture comes into play. By combining a solid replication strategy with intelligent proxying and a next-generation caching layer, we can overcome these challenges and build a highly performant and resilient system.
The Foundation: Master-Slave with GTID and Semi-Sync Replication
The bedrock of any scalable MySQL architecture is a reliable replication setup. This setup comes from Facebook's production experience: it has been used in production at scale until they developed a closed source fork of MySQL implementing Raft as a consensus algorithm to reach an indipendent, in-process and fully automatic replication consistency mechanism thus enabling the automated leader (aka writer) promotion process in case of failure.
While the effort might be worth in case of a "multi terabyte, sharded and geo-replicated" deployment like Facebook's, which, according to the rumor, seems to be the biggest ever by far, semi-sync replication works perfectly for my own case and perhaps it also does for the large majority of scenarios out there. And, don't forget, it has been working in production flawlessly for a decade at the Facebook, at the top of its popularity.
Semi-sync replication and GTID-mode make you forget the old, error-prone method of tracking binary log files and positions, at least. Modern MySQL deployments should standardize on semi-sync and Global Transaction Identifiers (GTID).
A GTID (Global Transaction Identifier) is a unique ID assigned to every transaction committed on the primary server. This identifier simplifies replication management and failover activities. With GTID-based replication, you no longer need to manually manage complex binary log positions; servers can automatically identify which transactions have been applied. This is enabled by setting MASTER_AUTO_POSITION=1 on the replica, which allows it to find the correct starting point in the primary's transaction stream automatically. This dramatically simplifies failover and makes promoting a new primary a faster and less error-prone process.
Asynchronous Replication
By default, MySQL replication is asynchronous, meaning the primary commits a transaction without waiting for any replicas to receive it. This creates a risk of data loss if the primary crashes before the transaction is transmitted.
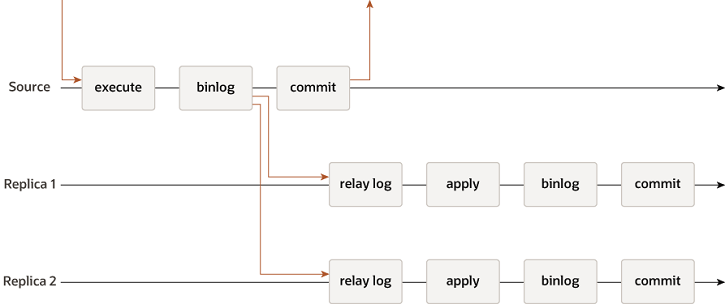
Semi-Synchronous Replication
Semi-synchronous replication mitigates this risk by requiring the primary to wait for an acknowledgment from at least one replica before confirming the commit to the client.
It's a balance: you gain significant data durability without the high latency penalty of a fully synchronous system. This setup is ideal for ensuring that any transaction reported as successful to an application has been safely recorded on the "relay log" (which is ahead of the replica's binlog) of one other server at least, since the number of voters is configurable via a system variable. And you may also choose to setup a timeout that allows you to automatically turn off the semi-sync transaction's remote ack enforcement whenever the quorum is missed for a certain amount of time.
An important benefit of semi-sync replication is that it acknowledges transactions based on relay log persistence, not on the application of changes. Even if a replica's SQL thread is lagging behind in applying transactions to its database, the semi-sync acknowledgment still occurs as soon as the transaction is written and flushed to the relay log. This means that data durability is guaranteed regardless of apply lag, which can occur due to long-running transactions, heavy workloads, or replica resource constraints. That's the main difference when compared to a multi-master and synchronous replication.

The Traffic Cop: ProxySQL with its Binlog Reader
With a solid replication foundation, the next step is to manage traffic intelligently. ProxySQL is a high-performance SQL proxy that sits between your applications and your database cluster. It provides essential features like read-write splitting, query routing, and multiplexing.
The real game-changer is ProxySQL's ability to provide GTID-consistent reads. This directly solves the classic problem of "read-after-write" inconsistency, where an application writes data to the primary and a subsequent read from a replica returns stale data because the replica hasn't caught up yet.
ProxySQL achieves this through a component called the mysql-binlog-reader. Here's how it works:
A lightweight proxysql-mysql-binlog process runs on each MySQL server (primary and replicas).
This process connects to its local MySQL instance as if it were a replica, reading the binary log in real-time.
It streams the GTID of every transaction that has been executed on that server back to all ProxySQL instances.
When an application issues a write through ProxySQL, ProxySQL tracks the GTID returned by the primary upon a successful commit.
When a subsequent read query arrives for that same session, ProxySQL consults its real-time GTID information and routes the query to a replica that is guaranteed to have already applied that transaction's GTID. If no replica is up-to-date, the query is safely routed to the primary.
This setup provides causal read consistency out of the box, eliminating stale reads without requiring complex application logic.
The Accelerator: ReadySet Caching with Change Data Capture (CDC)
Even with optimized queries and intelligent routing, some read queries remain expensive. This is where we can address MySQL's lack of materialized views with a next-generation caching solution like ReadySet.
Readyset is not a typical time-to-live (TTL) cache. Instead, it acts as a smart, wire-compatible caching engine that connects directly to your MySQL database. The magic lies in its use of Change Data Capture (CDC):
Replication-Based Caching: ReadySet connects to your MySQL primary as a replica. It listens to the binary log stream, just like another replica server.
Automatic Cache Updates: When you cache a SELECT query in ReadySet, it doesn't just store the result. It understands the query's underlying data dependencies. As INSERT, UPDATE, or DELETE operations occur on the primary, ReadySet sees these changes in the replication stream and incrementally and automatically updates its cached results in real time.
Transparent Integration: Since ReadySet is wire-compatible with MySQL, you can point your application to it by simply changing the connection string. Unsupported queries are transparently passed through to the underlying database.
Moreover, Readyset can be easily integrated with ProxySQL to automatically create routing rules according to the view's availability. This can be done using Readyset ProxySQL Scheduler. It'll orchestrate automatically the routing decisions on your behalf by automatically detecting the queries to be cached and registering their capturing rules in ProxySQL.
This approach effectively gives you on-the-fly materialized views for your most demanding SELECT queries. For queries that aggregate millions of rows, the response time can drop from seconds to milliseconds. This dramatically reduces the load on your primary and/or on your secondary databases and provides blazing-fast read performance without any changes to your application code.
A good compromise to scale out and speed up query exec times
By combining these technologies, we create a synergistic system that is fast, resilient, and scalable:
Writes are sent through ProxySQL to the primary MySQL server. The commit is confirmed only after semi-sync replication acknowledges the transaction has been received by at least one replica, ensuring durability.
- Reads are also sent to ProxySQL.
If the query is a candidate for caching, it can be directed to a ReadySet hostgroup within ProxySQL. ReadySet, kept up-to-date via CDC, serves the result from its in-memory cache at sub-millisecond latencies.
For non-cached reads, ProxySQL uses its GTID awareness to route the query to a read replica that is guaranteed to have the necessary data, preventing stale reads.
This multi-layered approach addresses the initial challenges of performance, concurrency, and data freshness, transforming a standard MySQL setup into a modern, high-performance data infrastructure with horizontal scalability and fast data access.